赌钱app下载Claude 的行为格式就随着变-押大小的赌博软件「中国」官网下载

 赌钱app下载
赌钱app下载
【新智元导读】Anthropic用40万次会话Claude Code实锤:能从 AI 身上榨出几倍产能的,不是代码力,是更懂行。
一个从没写过一排代码的管帐,能不颖异翻科班要害员?
听起来像言三语四。
就在昨天,Anthropic 甩出一份重磅进展,把这个反直观的谜底,用 40 万次的确会话砸到了台面上——能,况兼差距小到险些不错忽略不计。

在秘籍保护的前提下,Anthropic「卧底」分析了 2025 年 10 月到 2026 年 4 月、约 23.5 万名用户产生的近 40 万次 Claude Code 交互数据。
他们把每一次会话远隔揉碎,分析用户干了什么活、谁在拍板、效果奈何样——最终得出一个毒害颠覆通盘这个词行业默契的论断:
决定一次 AI 编程成败的,不是你的代码功底,而是你对我方那行的相识有多深。
换句话说,AI 编程不仅没把生手拒之门外,反而成了百行万企「懂哥」们的封神外挂。
如今 Claude Code 的用户平均每周要泡在这个器具上 20 个小时——一周五天,一天四小时,比好多东说念主作陪家东说念主的工夫还长。
一个直击灵魂的问题随之而来:这种器具的狞恶滋长,到底会把学问型打工东说念主的改日推向何方?
Anthropic 这份进展,等于用的确数据给出的第一个早期信号。
东说念主决定造什么,AI 决定奈何造
先看一组实锤数据。
Anthropic 建了一个「有计算归因分类器」,把每次会话里的每一个要害决定掰开来看:哪些是「计算有计算」——作念什么、走哪条路、什么算完成;哪些是「实践有计算」——改哪个文献、写什么代码、用什么谈话、跑什么敕令。
然后,一一标注是东说念主作念的,如故 Claude 作念的。
效果极其澄清:东说念主类作念了能够 70% 的计算有计算,Claude 包揽了能够 80% 的实践有计算。
一句话回归:东说念主决定造什么,智能体决定奈何造。
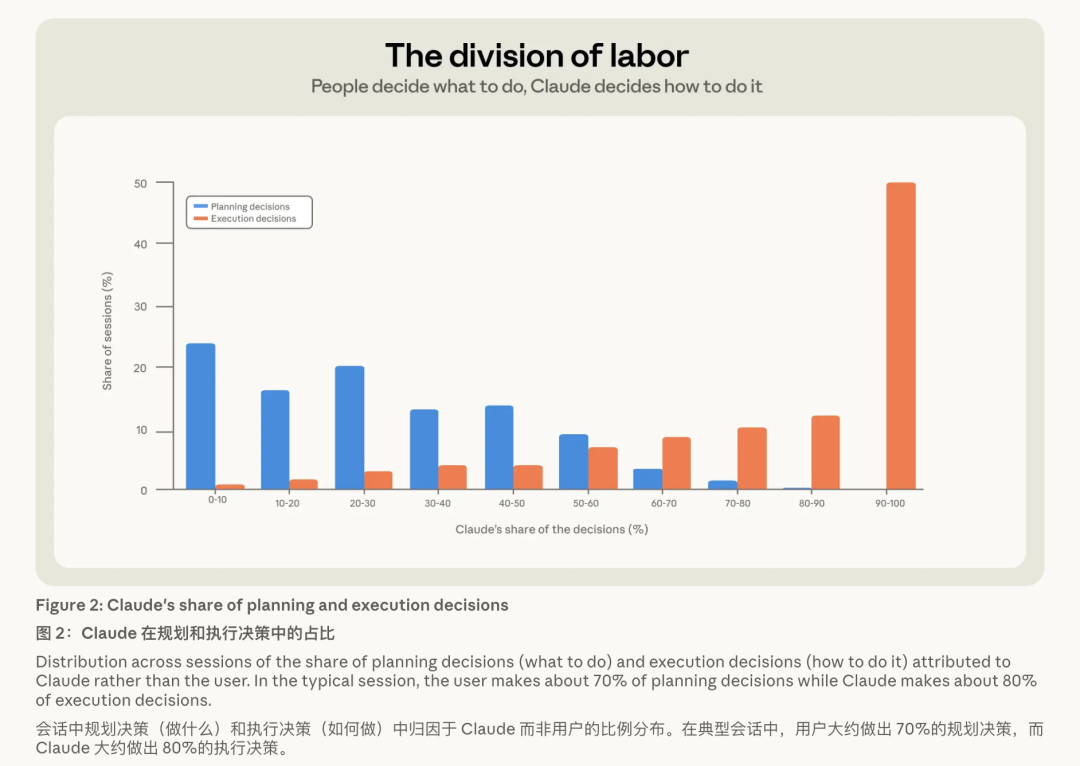
你只管说了了要什么,剩下的脏活累活,它全干了。
况兼,谁掌捏主动权,Claude 的行为格式就随着变。
当用户紧捏实践有计算权(作念了进步 80% 的实践决定),Claude 每轮只作念能够 8 个作为,乖乖听指引;而当 Claude 拿到了计算主导权(作念了进步 80% 的计算决定),它每轮径直飙到 16 个作为——器具放开缰绳,马力就拉满。
这种默契的东说念主机单干,像极了一个东说念主带着一支万能实践团队:你不需要躬行搬砖,但你必应知说念这屋子该奈何盖。

懂行的东说念主,一句话顶别东说念主五句
最颠覆的,是「专科度」这个词在进展里的界说——它跟你的职位头衔毫无关系,而是任务特定的。
一个资深工程师第一次问 Rust,在 Rust 这件事上等于个新手;而一个从没碰过 Python 的管帐,只消他能精准告诉 Claude 月末对账必须卡住哪几条纪律、还能一眼揪出 AI 漏掉的领域情况,那他在这个任务上,等于实事求是的大众。
这才是这份进展最机敏的知悉:专科度不是「你会什么器具」,而是「你对问题自己的相识深不深」。
数据有多悬殊?
新手会话里,每条领导只触发约 5 个 Claude 作为、约 600 词输出;而大众会话,作为链翻倍到 12 个,输出飙到 5 倍——3200 词。
这个差距在每一种责任类型、每一个任务价值区间里皆闲暇存在。
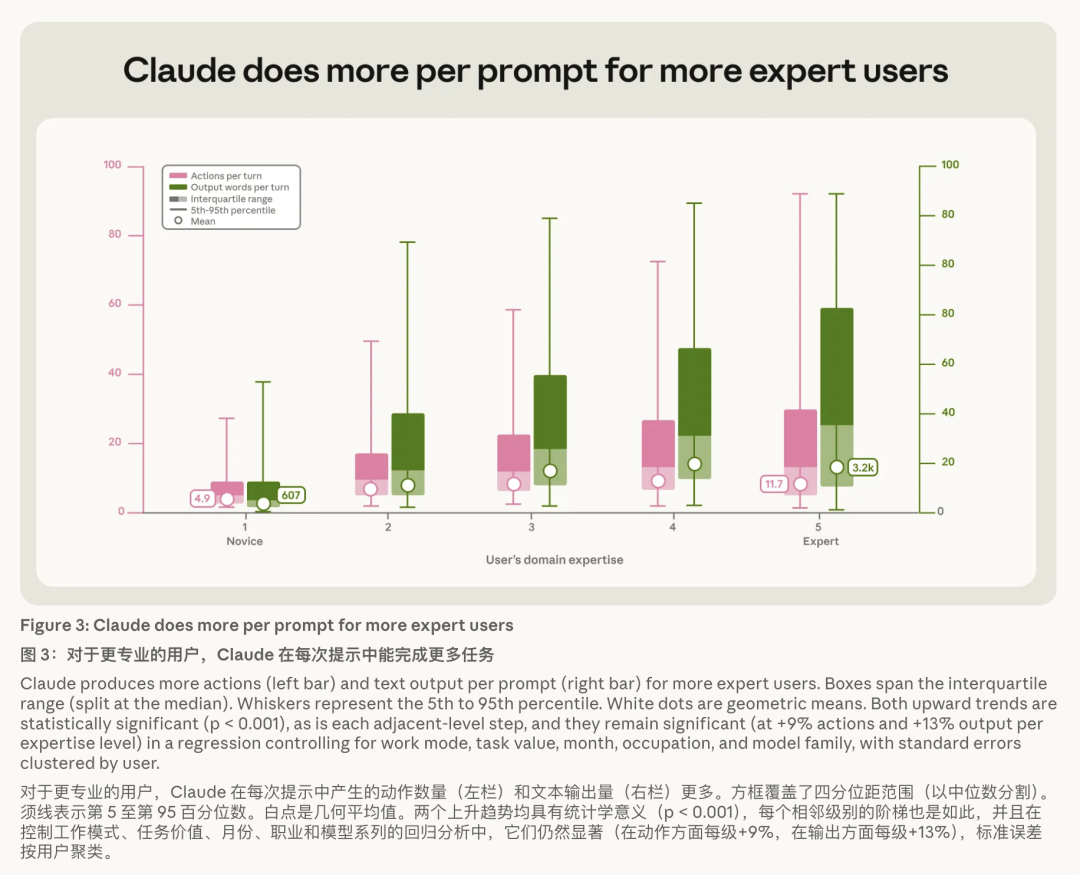
一样一个 AI,懂行的东说念主能榨出几倍的产能。差距不在器具,在脑子。
新手最容易撂挑子
到底谁用得更得胜?
进展给出的谜底,依然指向「懂行」二字。
Anthropic 想象了一套极其严格的得胜评估体系。他们先让分类器通读齐备会话纪录,判断用户是否完成了绸缪,再类似「硬把柄」考证——必须有 git 提交、测试通过、或用户明确阐发这类可查证的信号。
按这个最严格的口径:新手会话只消 15% 达标,中级用户跳到 28%,高等和大众更是到了 33%。
但最要害的信息藏在这条弧线的式样里——最大的那一跃,发生在「从新手到中级」。
也等于说,你不需要成为某个规模的绝世能手,只消有「够用的把捏」,就能拿走大部分成利。
从中级到大众,收益弧线较着变平了。
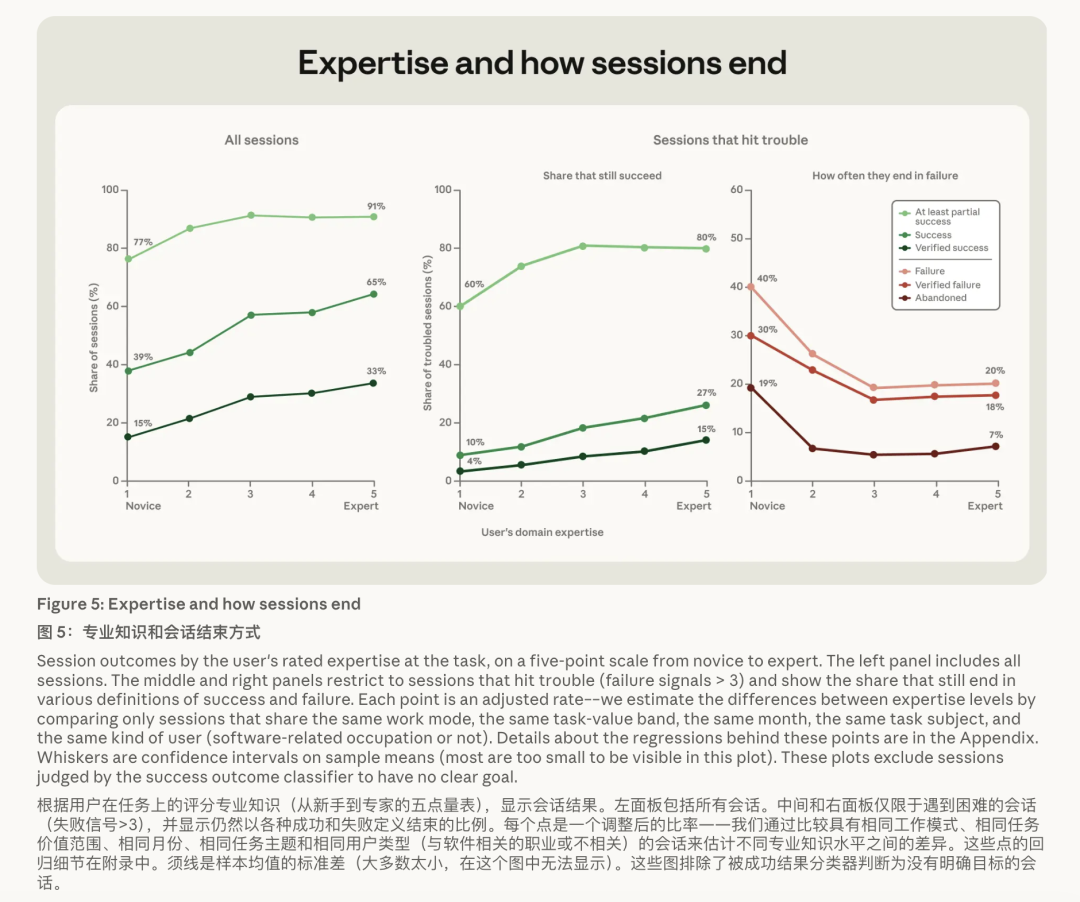
碰壁时的差距更扎心。
当会话出错、反复重试、用户开动骂街——Anthropic 管这叫「碰到清贫」的会话——新手最终翻盘(在「遇清贫」前提下仍考证得胜)的概率只消 4%,大众是 15%。
大众不是不会碰壁,而是碰了壁知说念奈何把 AI 拉回正说念。
更扎心的:那些「判定失败、且一排代码皆没写就废弃」的会话里,19% 的新手径直撂了挑子,其他教学水平的东说念主只消 5%–7%。
最没教学的东说念主,一碰到坎就伊始认输——他们不是输在智商上,是输在不知说念下一步该跟 AI 说什么。
奇迹?反而没那么弥留了
至于你是要害员如故讼师如故家具司理?
说真话,没那么弥留了。
Anthropic 用好意思国劳工统计局(BLS)的模范奇迹分类体系,把用户映射到 23 个大类。
分类器被明确要求:弗成因为在写代码,就以为他是要害员。
一个讼师用 Claude 写了一个自动审公约条件的剧本,他依然被归为法律从业者——因为他的中枢责任是法律,代码仅仅杀青主见的妙技。
在这个分类基础上,软件关联奇迹的考证得胜率约 30%,其他奇迹约 26%;在的确产出代码的会话里是 34% 对 29%。
若是看更往往的「至少部分得胜」模范,差距更是缩到只剩 1 个百分点——89% 对 88%。
数据集里最大的十个奇迹,得胜率齐全落在软件工程师 7 个百分点以内。况兼这个差距在七个月里既莫得扩大,也莫得平缓——双方的得胜率在同步莳植。
最不测的是:解决岗的考证得胜率,以至略高于要害员。
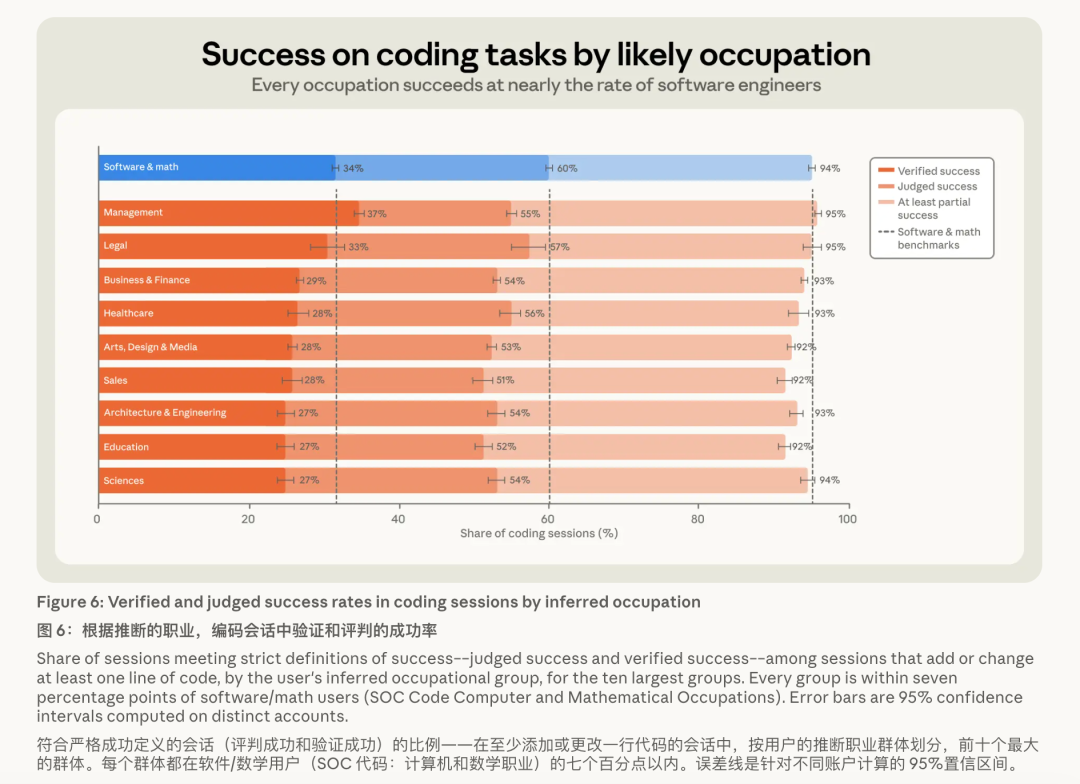
Anthropic 我方也分析了原因——这可能是因为解决者更善于在对话中明确抒发「我要的等于这个」,也可能是指引 AI 这件事和带团队本等于吞并种智商:把需求拆了了、把标的定清晰、在要害节点作念判断。
这个发现险些不错重写「AI 期间谁最值钱」这个命题——谜底不是最会写代码的东说念主,而是最会界说问题的东说念主。
这仅仅一份初步答卷
诚然,Anthropic 我方把话说得很克制。
他们承认看不到的确的业务效果——所谓「得胜率」来自对会话纪录的分类判断,不等于这段代码最终被接纳、简直产生了生意价值。
论断是初步的,别神化。
但标的仍是毒害澄清,澄清到让东说念主后背发凉:在 AI 编程里,写代码的门槛正在被抹平,而「懂业务」的价值正在被疯浮松大。
Claude Code 上正在发生的这一切,很可能仅仅通盘这个词学问型责任改日走向的一次预览——
代码谁皆能让 AI 写赌钱app下载,但能弗成把问题思了了、把需求提到点子上,才是这个期间真有时钱的武艺。